


Introduction: The RAG Obsession and a Provocative Question
The field of artificial intelligence has witnessed a rapid evolution, with Large Language Models (LLMs) emerging as transformative tools. A few years ago, the AI community was captivated by Retrieval-Augmented Generation (RAG), a paradigm that quickly became the standard for grounding LLMs and mitigating their inherent tendency to "hallucinate" or invent information.1 This involved a complex pipeline of building vector databases, meticulously chunking documents, creating embeddings, and managing intricate retrieval systems, all with the goal of enabling LLMs to accurately answer questions based on proprietary or external knowledge.3
As the industry progresses into 2025, a critical question arises: Is RAG, in its traditional, complex form, truly obsolete? The rapid advancements in LLM capabilities, particularly the expansion of their context windows, alongside the emergence of highly optimized auxiliary tools, prompt a re-evaluation of those once-essential intricate RAG pipelines [User Query]. This is not merely an academic discussion; it carries significant implications for how AI systems are architected and deployed in real-world scenarios.
While the answer is nuanced, it is clear that RAG is far from dead. Its fundamental value proposition remains strong. However, for many common documentation-based Q&A systems, the traditional RAG approach may no longer be the optimal first choice. The emerging trend for these applications leans towards simplicity and efficiency. This report aims to challenge conventional wisdom by offering a fresh perspective on the current state of RAG, exploring its evolution, inherent limitations, and the compelling alternatives that have emerged. A practical case study of a simpler Q&A agent will be examined, comparing costs and performance, and delving into the intriguing concept of "Thinking vs. Non-Thinking Models." The objective is to provide actionable insights for technology professionals facing critical architectural decisions in the current AI landscape [User Query].
The Rise and Realities of Traditional RAG
RAG's Core Value Proposition: Why It Became Essential
Traditional Large Language Models, despite their impressive generative capabilities, inherently possess limitations. They are trained on fixed datasets, which means their knowledge is static and cannot dynamically update.3 A significant challenge is their propensity for "hallucination," where they produce plausible-sounding but factually incorrect or entirely fabricated information.1 This unreliability posed a substantial barrier to their adoption in professional and technical settings where accuracy is paramount.
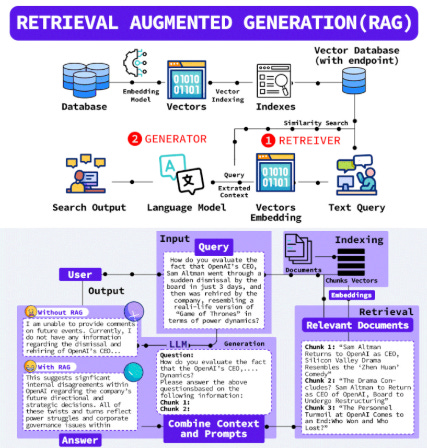
Retrieval-Augmented Generation emerged as a groundbreaking solution, effectively providing LLMs with a "fact-checking superpower".1 By enabling LLMs to dynamically retrieve relevant, verifiable information from external knowledge bases—such as company documents, databases, or the web—before generating a response, RAG grounds the output in current and contextually accurate data.1 This hybrid approach has demonstrably improved factual accuracy, with organizations reporting a 20-30% reduction in hallucinations.1 Furthermore, RAG provides access to real-time and updated information, overcoming the static nature of LLM training data cutoffs.1 It also significantly enhances domain-specific knowledge handling, allowing LLMs to adapt to specialized fields like law, medicine, or finance without requiring extensive and costly retraining.1 A key benefit for enterprise applications is the improved interpretability and transparency, as RAG systems can cite the specific sources from which information was retrieved, providing an audit trail for verification.1 These foundational advantages cemented RAG's position as an indispensable component for robust, enterprise-grade AI applications where factual correctness and up-to-date information are non-negotiable.2
Unpacking Traditional RAG's Limitations in 2025: The Hidden Costs of Complexity
Despite its undeniable benefits, traditional RAG, as widely implemented, has revealed several limitations that have become more pronounced by 2025. These challenges often translate into hidden costs and operational burdens.
The most prominent issue is the complexity and maintenance overhead associated with traditional RAG systems.4 The RAG process involves several intricate steps: encoding the user query, retrieving relevant documents, fusing the retrieved context with the query, and finally generating the response.3 This multi-stage pipeline often necessitates the setup and ongoing management of specialized infrastructure, including vector databases, embedding models, and sophisticated chunking strategies for documents.5 The operational burden of this complexity is substantial. It is not merely a technical hurdle but a critical business and operational challenge that significantly impacts the Total Cost of Ownership (TCO). This translates directly into higher engineering effort, a prolonged time-to-market for new applications, and a persistent need for specialized talent proficient in areas such as vector database management, embedding model selection, and optimal chunking strategies.4 Developers frequently highlight "data unification" as a primary challenge, emphasizing that RAG's effectiveness is heavily contingent on a well-organized and meticulously prepared knowledge base.7 This substantial operational investment makes simpler, more streamlined alternatives increasingly attractive for common use cases.
Another significant challenge stems from retrieval quality and accuracy issues.3 The efficacy of a RAG system is heavily dependent on the retriever's ability to provide accurate and relevant documents. If the retrieved content is irrelevant, outdated, or biased, the generated response will inevitably be flawed, leading to misinformation or contextual misalignment.4 Even when presented with accurate retrieved documents, the generative model can still misinterpret or distort the content, or even hallucinate new information.3 This means that while RAG mitigates hallucinations, it does not entirely eliminate them, and its performance remains sensitive to the quality of its input data.
Furthermore, traditional RAG systems often suffer from high latency.3 This is frequently attributed to the common practice of dividing documents into small chunks, typically around 100 words.3 While this approach enables fine-grained searching, it drastically increases the search space. Retrievers must sift through millions of these small units—up to 22 million for open-domain tasks like Wikipedia—to find relevant information, which significantly increases latency and resource consumption.3 This reveals a fundamental trade-off inherent in traditional RAG's design: achieving maximum precision through granular retrieval comes at the expense of increased search overhead and response time. This trade-off is increasingly being challenged by alternative approaches, such as large context windows or optimized search APIs, which suggest that for many Q&A tasks, a less granular but faster retrieval (or direct ingestion) of larger, pre-ranked relevant blocks of information can be more efficient, prioritizing overall system efficiency and simplicity over micro-level retrieval granularity.
Finally, while RAG is acknowledged as more cost-efficient than continuous LLM retraining—potentially reducing operational costs by 20% per token, making it 20 times cheaper than constantly fine-tuning a traditional LLM 8—the
cost implications of the underlying infrastructure cannot be overlooked. The computational resources and infrastructure required for managing vector databases, generating and updating embeddings, and ongoing maintenance can still lead to higher operational costs compared to simpler, managed alternatives that offload much of this burden.4
The Contenders: Large Context Windows and Direct Search
The Ascent of Large Context Windows (LC): A New Frontier for LLMs
The landscape of Large Language Models is in constant flux, with a pivotal development being the dramatic expansion of their context windows.5 The context window defines the maximum amount of text (measured in tokens) an LLM can process and consider at any one time when generating responses.10 Historically, this was a significant limitation, with early models like GPT-1 (2018) having a context size of 512 tokens and GPT-3 at 2048 tokens.10 However, by 2025, models such as Gemini Pro 1.5/2.0 are capable of handling up to 2 million tokens, equivalent to approximately 15,000 pages of text, with experimental results suggesting performance up to 10 million tokens.10 This exponential increase fundamentally reshapes the amount of information an LLM can directly "see" and process in a single interaction.
The benefits of these expansive context windows are considerable. They enable LLMs to maintain coherence across lengthy conversations, grasp complex relationships within extensive documents, and reduce the tendency for hallucinations by providing a broader base of grounding information directly within the prompt.5 For tasks requiring a deep understanding of conversation history or intricate relationships within large datasets, long context windows offer a powerful solution.5
However, the advantages come with inherent challenges. Processing massive amounts of text within a large context window is computationally expensive and slow.5 The increased data volume translates directly into higher processing costs, particularly for very large inputs.11 While caching can mitigate some of these costs by storing previously processed contexts for reuse, its effectiveness diminishes with highly varied prompts.5
A more subtle but critical limitation is the "lost-in-the-middle" problem.2 Even with the capacity to ingest vast amounts of text, LLMs often struggle to effectively utilize specific content that is distributed across multiple parts of the input. Information located in the middle portions of a long input sequence can be overlooked or underutilized, leading to reduced accuracy.2 This observation highlights that raw context window size is not the sole determinant of performance. The organization and relevance of the information
within that context are equally crucial. This is where intelligent retrieval mechanisms, whether part of a RAG system or a specialized search API, demonstrate their value. By curating the context before it reaches the LLM, these mechanisms effectively mitigate the "lost-in-the-middle" problem by ensuring that the most important information is presented optimally (e.g., at the beginning or end of the context, where LLMs tend to perform best).12 This implies that even with large context windows, some form of "augmentation" remains beneficial for optimal performance, ensuring the LLM focuses on the truly relevant parts of the input.
Introducing the "Search-First" Alternative: Simplicity as a Feature
Given the complexities of traditional RAG and the nuanced challenges of large context windows, a "search-first" alternative has emerged as a compelling solution for specific use cases, particularly documentation-based Q&A systems.13 The core idea behind this approach is to bypass the complexities of building and maintaining a full RAG pipeline—with its vector databases, embedding generation, and chunking strategies—by instead leveraging highly optimized, external search APIs in conjunction with the expanded context windows of modern LLMs.13
This approach aims to deliver simplicity, speed, and cost-effectiveness by offloading the heavy lifting of data acquisition and relevance ranking to a specialized, managed service.14 Services like Tavily are purpose-built search engines optimized for AI agents, designed to provide real-time, customizable, and "RAG-ready" search results and extracted content in a single API call.14 Unlike traditional search APIs that return raw snippets and URLs requiring further scraping and filtering, Tavily dynamically searches, reviews multiple sources, and extracts the most relevant content, delivering it in a concise, ready-to-use format optimized for LLM consumption.14 This streamlined process significantly reduces the burden on developers, eliminating the need for complex infrastructure and ongoing maintenance associated with traditional RAG, while still ensuring factual accuracy and access to up-to-date information.13
Case Study: A Simple Q&A Agent Without Traditional RAG
The javiramos1/qagent GitHub project exemplifies the "search-first" alternative, presenting itself as a simpler and more practical solution for documentation-based Q&A compared to traditional RAG systems.13 This project demonstrates how modern search APIs, combined with the capabilities of large context window LLMs, can effectively eliminate the complexity and overhead traditionally associated with Retrieval-Augmented Generation for many common use cases.13
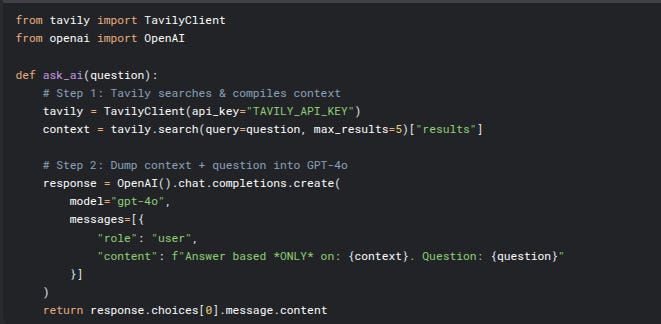
The javiramos1/qagent Architecture: A Blueprint for Simplicity
The qagent system is built on a search-first approach with intelligent fallback to web scraping.13 Its architecture comprises several core components designed for efficiency and minimal overhead:
Domain-Restricted Agent: A LangChain agent is utilized, specifically configured to search only within approved knowledge sources.13
Tavily Search Integration: The Tavily API serves as the primary search mechanism, enabling fast, targeted searches within specified documentation websites.13 Tavily is optimized for AI agents, providing structured and customizable search results, and handles the burden of searching, scraping, filtering, and extracting relevant information from online sources in a single API call.14
Web Scraping Tool: A Chromium-based tool acts as a fallback, performing comprehensive page content extraction when the initial search results from Tavily are deemed insufficient.13
Site Restrictions: Knowledge sources are easily configured and controlled via a simple CSV file (
sites_data.csv), ensuring searches remain within defined organizational boundaries.13Cost Control: The system incorporates intelligent tool selection logic to minimize expensive operations, prioritizing fast search over deep scraping when possible.13
Model Selection: The
qagentstrategically employs Gemini 2.0 Flash, a "non-thinking" model, over more reasoning-heavy models like GPT-4.13 This choice is driven by its cost-effectiveness and speed, as Gemini Flash is significantly cheaper and faster for tool-based workflows.13 The ReAct Framework is used to provide structured thinking and decision-making for the agent, effectively replacing internal reasoning with transparent, tool-driven logic at a lower cost.13
The two-tier information retrieval process is central to its efficiency:
Primary: Fast Search: The system first attempts a quick search using the Tavily API within the approved documentation websites.13
Fallback: Deep Scraping: If the initial search results do not provide sufficient information, the system automatically scrapes entire pages for more comprehensive content.13
The agent decision logic follows a smart escalation strategy: it analyzes the query to determine relevant documentation sites, executes a fast Tavily search, evaluates the results for sufficiency, and only resorts to scraping entire pages if necessary. Finally, it combines information from both search and scraped sources to generate detailed answers.13
Performance and Cost Advantages: Challenging RAG's Dominance
The qagent project makes compelling claims regarding its performance and cost advantages over traditional RAG systems.
Cost-Effectiveness:
The project provides a "Cost Reality Check" comparing its search-first approach with traditional RAG, using Gemini 2.0 Flash for a fair comparison.13
Search-First Approach (qagent): The estimated search cost is $0.075 for 1M input tokens + 1K output tokens, with no additional infrastructure needed.13
Traditional RAG Approach: The LLM cost is similar at $0.075. However, traditional RAG incurs additional overhead of approximately $0.002 for embeddings and vector database queries, plus an estimated $0.001 for hosting, maintenance, and pipeline management. This results in a total RAG cost of approximately $0.078, making it about 4% more expensive than the search-first approach for comparable LLM usage.13
Ultra-Affordable Option: By leveraging Gemini 2.0 Flash-Lite, the cost can drop to $0.005 per query for a 128K context, which is claimed to be 15 times cheaper than traditional RAG.13
These figures suggest that the search-first approach significantly reduces or eliminates the need for vector databases, embeddings, chunking, and ongoing maintenance overhead.13 Furthermore, because it relies on real-time search, the knowledge base is "always fresh," avoiding issues of stale embeddings or the need for frequent index updates.13
Performance Advantages:
The qagent repository asserts several performance benefits for its search-first methodology:
No "Lost-in-the-Middle" Issues: By retrieving the most relevant content first via search, the approach inherently avoids the problem where LLMs might overlook crucial information buried within large, unfiltered contexts.13 Search algorithms are specifically optimized for query relevance, ensuring the LLM receives highly pertinent information.13 This directly addresses the observation that simply increasing context window size doesn't guarantee optimal performance; the
organization and relevance of information within that context are crucial.
Faster Iteration and Simpler Debugging: Since there's no embedding regeneration required when documents change, iteration cycles are faster.13 Debugging is also simpler, as it's easy to trace what content was retrieved and why, enhancing transparency.13
Overall Speed and Efficiency: The system is optimized for performance, with fast search handling 90% of queries, and deep scraping only activated when strictly necessary.13 Optional intelligent summarization of search results can further reduce token usage by 60-80%, leading to 2-3 times faster processing with smaller contexts, lower costs, and a better focus on query-relevant information.13
These advantages suggest that for many documentation-based Q&A systems, the search-first approach offers a compelling blend of simplicity, cost-effectiveness, and performance, challenging the traditional RAG paradigm.
Thinking vs. Non-Thinking Models
The discussion around RAG and its alternatives often intersects with the evolving understanding of how LLMs "think" or process information. This leads to a distinction between "Thinking LLMs" and "Non-Thinking Models."
The Concept of "Thinking LLMs"
The concept of "Thinking LLMs" is explored in research such as "Thinking LLMs: General Instruction Following with Thought Generation" (Wu et al., 2024).16 This approach enables an LLM to generate internal thoughts
before producing its final output, a critical skill that traditional LLMs typically lack.16 The core idea is
Thought Preference Optimization (TPO), a reinforcement learning method designed to train LLMs to "think" effectively across various tasks.16
The TPO method involves several steps: the LLM is prompted to generate internal thoughts that remain hidden from the user but influence the final output. Multiple outputs (thoughts and responses) are generated, and a separate "judge model" evaluates only the responses to determine the best and worst outcomes. Using these preference pairs, the LLM is further trained using Direct Preference Optimization (DPO) to refine its internal thought processes for improved responses.16 This method has demonstrated superior performance not only in traditional reasoning tasks but also in non-reasoning domains like marketing and creative writing, with TPO-trained models achieving higher win rates on benchmarks like AlpacaEval and Arena-Hard compared to direct-response counterparts.16 This suggests that, much like humans, AI can benefit from an internal deliberation process before formulating a response.
"Non-Thinking Models" and Tool-Use
In contrast to "Thinking LLMs" that generate internal thought processes, "Non-Thinking Models" or standard LLMs, while powerful, primarily focus on generating responses based on their training data and the immediate prompt.16 They do not explicitly simulate an internal deliberation or reasoning process. However, the rise of tool-use frameworks, such as the ReAct Framework utilized by
qagent, allows these "non-thinking" models to achieve complex behaviors that mimic reasoning.13
By integrating external tools—like search APIs, web scrapers, or code interpreters—LLMs can execute multi-step operations. The ReAct Framework, for instance, enables an LLM to alternate between "thought" (planning the next action) and "action" (using a tool).13 This externalized process provides structured thinking at a lower cost and with transparent logic, effectively replacing internal, computationally expensive reasoning with a series of observable tool calls.13 The
qagent's strategic choice of Gemini 2.0 Flash, a "non-thinking" model, combined with tools like Tavily Search, exemplifies this approach, prioritizing cost-effectiveness and speed for specific Q&A workflows.13
The Nuance of Reasoning Capabilities
While Large Reasoning Models (LRMs) have shown improved performance on reasoning benchmarks and an advantage in medium-complexity tasks, their fundamental capabilities and limitations are still being understood.17 Research indicates that frontier LRMs can experience a complete accuracy collapse beyond certain complexities and exhibit a counter-intuitive scaling limit where reasoning effort declines despite adequate token budgets.17 Surprisingly, for low-complexity tasks, standard LLMs can even outperform LRMs.17 Furthermore, LRMs have shown limitations in exact computation, failing to use explicit algorithms and reasoning inconsistently across different problems.17
This suggests that while "thinking" capabilities are advancing, they are not a panacea. For many practical applications, particularly those focused on information retrieval and synthesis from external sources, a well-designed "non-thinking" model augmented with efficient and specialized tools can deliver comparable or superior performance at a significantly lower cost and complexity. The choice between a "thinking" model and a "non-thinking" model with robust tool integration depends heavily on the specific task requirements, complexity, and resource constraints.
The Future of Documentation-Based Q&A Systems
The landscape of AI-powered Q&A systems, particularly for documentation, is evolving rapidly. While traditional RAG faces scrutiny due to its complexity and emerging alternatives, its core principles remain relevant, albeit in more advanced forms.
RAG's Evolution: Advanced Techniques and Hybrid Models
RAG is not static; it is undergoing continuous innovation. The "simpler forms of RAG, which chunk and retrieve data in trivial ways, might be seeing a decline," but "more complex RAG setups are far from fading away".12 Advanced RAG techniques are addressing past limitations:
Long RAG works with larger retrieval units to reduce fragmentation and improve efficiency, solving issues like loss of context and high computational overhead associated with small chunks.3
Self-RAG and Corrective RAG introduce mechanisms for the model to critically evaluate retrieved information and its own generated responses for relevance and accuracy.3
Graph RAG integrates graph-structured data to enhance knowledge retrieval and generation, unlocking the potential of graph-based knowledge for improved AI-driven reasoning.3
Multimodal RAG is extending beyond text to incorporate images, videos, and audio, allowing AI systems to evaluate and retrieve data from diverse external sources for a more comprehensive experience.1
Agentic RAG enhances traditional RAG by integrating autonomous AI agents to improve retrieval strategies, contextual refinement, and workflow adaptability, enabling flexible and scalable multi-step reasoning.18 These systems use agentic design patterns like reflection, planning, and tool use.18
OP-RAG (Order-Preserve RAG) improves quality in long-context Q&A by preserving the original order of retrieved document chunks, even when selecting based on relevance. This maintains logical progression, which is crucial for coherent and accurate responses, and has shown superior results with fewer tokens compared to long-context LLMs.12
The future also points towards hybrid models that combine keyword search with sophisticated retrieval techniques like knowledge graphs and semantic search, optimizing the retrieval process and improving response accuracy.19 This suggests a move towards intelligently combining the strengths of various approaches rather than relying on a single method.
Alternatives and Complementary Approaches
Beyond advanced RAG, several alternatives and complementary strategies are emerging for Q&A systems:
Knowledge-Augmented Generation (KAG): This approach tightly integrates curated, domain-specific knowledge (e.g., FAQs, internal wikis) directly into the model's memory or context window, reducing the need for constant external search.20
Cache-Augmented Generation (CAG): CAG leverages previously asked questions and their responses by storing them in a cache. When similar queries arise, the model references the cached answer, significantly speeding up responses to common inquiries.9
Instruction Fine-Tuning: This method focuses on training the AI to better follow specific instructions by providing example prompts and desired responses, aligning the model with business goals without altering data retrieval systems.20
Reinforcement Learning with Human Feedback (RLHF): RLHF enhances AI alignment with human preferences by allowing real people to evaluate responses and guide the model during training, leading to more helpful, less biased, and safer AI behavior.20
The choice between RAG, large context windows, search-first approaches, or these alternatives depends on specific business needs, user expectations, and data availability.20 Many organizations may benefit from a
hybrid model that combines two or more techniques, dynamically routing queries to the most appropriate solution.10 For instance, queries requiring current, domain-specific information might be routed to a RAG system, while those needing a comprehensive understanding of a long context could be directed to a large context LLM.21 This approach optimizes both cost and performance, achieving comparable results with reduced token usage.21
The Role of Search APIs and Scalable Infrastructure
The "search-first" approach, as demonstrated by qagent leveraging Tavily, highlights the growing importance of specialized search APIs in the AI ecosystem.13 These APIs are purpose-built for LLMs, handling the complexities of web search, scraping, filtering, and content extraction to deliver RAG-ready results efficiently.14 They offer real-time, customizable, and reliable information, reducing the burden on developers and eliminating the need for complex, self-managed retrieval infrastructure.14
The future also emphasizes RAG as a Service, with cloud-based solutions enabling businesses to deploy scalable and affordable RAG architectures without significant infrastructure investments.19 Companies like Google and Dropbox are expected to build their own RAG solutions, covering 90% of common use cases, but there will still be room for standalone products and specialized frameworks like LangChain, LlamaIndex, and Haystack, which are focusing on production-readiness, advanced retrieval strategies, and enterprise-grade features.7 The ability to integrate real-time data feeds into RAG models will become crucial, particularly in sectors requiring constant data updates.19
Conclusion
The provocative question, "Is RAG Dead?!", elicits a nuanced answer in 2025: No, traditional Retrieval-Augmented Generation is not dead, but its role is evolving, and for many common documentation-based Q&A systems, it should no longer be the default first choice. The initial obsession with building complex RAG pipelines was driven by the critical need to ground LLMs in factual, up-to-date information and mitigate hallucinations. RAG successfully addressed these challenges, offering enhanced accuracy, real-time data access, and domain-specific knowledge handling.
However, the inherent complexities of traditional RAG—including significant maintenance overhead, potential retrieval quality issues, and high latency due to granular chunking—have become increasingly apparent. These factors contribute to a higher Total Cost of Ownership and slower deployment cycles, prompting a re-evaluation of its universal applicability. The practice of dividing documents into small chunks, while enabling fine-grained search, creates a vast search space that can lead to increased latency and computational burden. This suggests a shift in optimization from granular retrieval to overall system efficiency and simplicity.
Concurrently, the dramatic expansion of LLM context windows has introduced a powerful alternative, allowing models to directly process vast amounts of information. While beneficial for coherence and reducing hallucinations, large context windows introduce their own challenges, notably increased computational cost and the "lost-in-the-middle" problem, where LLMs struggle to effectively utilize information buried within extensive inputs. This highlights that raw context size alone is insufficient; the organization and relevance of information within that context are paramount.
The emergence of "search-first" approaches, exemplified by the javiramos1/qagent project, offers a compelling solution for documentation-based Q&A. By leveraging highly optimized external search APIs like Tavily in conjunction with large context windows, these systems achieve simplicity, cost-effectiveness, and strong performance without the need for complex, self-managed RAG infrastructure. This approach eliminates the overhead of vector databases, embeddings, and chunking, providing always-fresh information and simpler debugging.
Looking ahead, RAG is not disappearing but is advancing through sophisticated techniques like Long RAG, Self-RAG, Graph RAG, Multimodal RAG, and Agentic RAG, which address its limitations and expand its capabilities. Hybrid models that combine RAG with large context windows or other alternatives like KAG and CAG are also gaining traction, allowing for dynamic routing of queries to the most appropriate solution. The distinction between "thinking" and "non-thinking" LLMs further underscores that for many practical applications, a "non-thinking" model augmented with efficient external tools can deliver comparable or superior results at a lower cost and complexity.
In conclusion, for many documentation-based Q&A systems in 2025, starting simple with a search-first approach leveraging modern search APIs and large context windows often proves to be a more efficient, cost-effective, and practical solution than building and maintaining traditional RAG pipelines. While RAG continues to evolve and remain indispensable for complex, specialized, or multimodal tasks, its simpler alternatives are redefining the baseline for accessible and performant AI applications. The future of Q&A lies in intelligently selecting and combining these evolving technologies to match specific application needs, prioritizing simplicity and efficiency where possible.
References
Retrieval-Augmented Generation in 2025: Solving LLM's Biggest Challenges
RAG, or Retrieval Augmented Generation: Revolutionizing AI in 2025
15 Pros & Cons of Retrieval Augmented Generation (RAG) [2025]
Context Size and the Power of RAG , February 2025 , Georgios Kaleadis (CTO at Satellytes)
Understanding Context window and Retrieval-Augmented Generation (RAG) in Large Language Models
https://docs.tavily.com/faq/faq
https://docs.tavily.com/documentation/about
Thinking LLMs: General Instruction Following with Thought Generation (Paper Explained) , Sebastian Buzdugan, 2024
Parshin Shojaee et al. 2025, The Illusion of Thinking: Understanding the Strengths and Limitations of Reasoning Models via the Lens of Problem Complexity
Trends in Active Retrieval Augmented Generation: 2025 and Beyond, Sachin Kalotra , 2025
15 Best Open-Source RAG Frameworks in 2025, Mark Ponomarev
Zhuowan Li et al. 2024, Retrieval Augmented Generation or Long-Context LLMs? A Comprehensive Study and Hybrid Approach
Quinn Leng et al. 2024, Long Context RAG Performance of Large Language Models
Peng Xu et al. 2024, RETRIEVAL MEETS LONG CONTEXT LARGE LANGUAGE MODELS